lesson 2:ollama本地模型调用
环境
安装
windows上下载安装ollama:ollama
ollama的application可以安装到电脑的任意路径,但是模型等记录一开始是默认安装到C:\Users\[user_name].ollama的
可以通过以下方式修改ollama模型等记录的路径:
- 退出ollama客户端
- 编辑系统环境变量:新建一个系统环境变量,命名为
OLLAMA_MODELS,路径添加为本地磁盘的任意路径 - 保存确定之后,重新开启ollama客户端
- 详见change ollama models locations
ollama的github地址如下:
拉取模型和运行测试
在ollama官网的Models标签找到想要下载到本地的大模型,选择对应的模型参数,直接复制指令到终端下载即可:
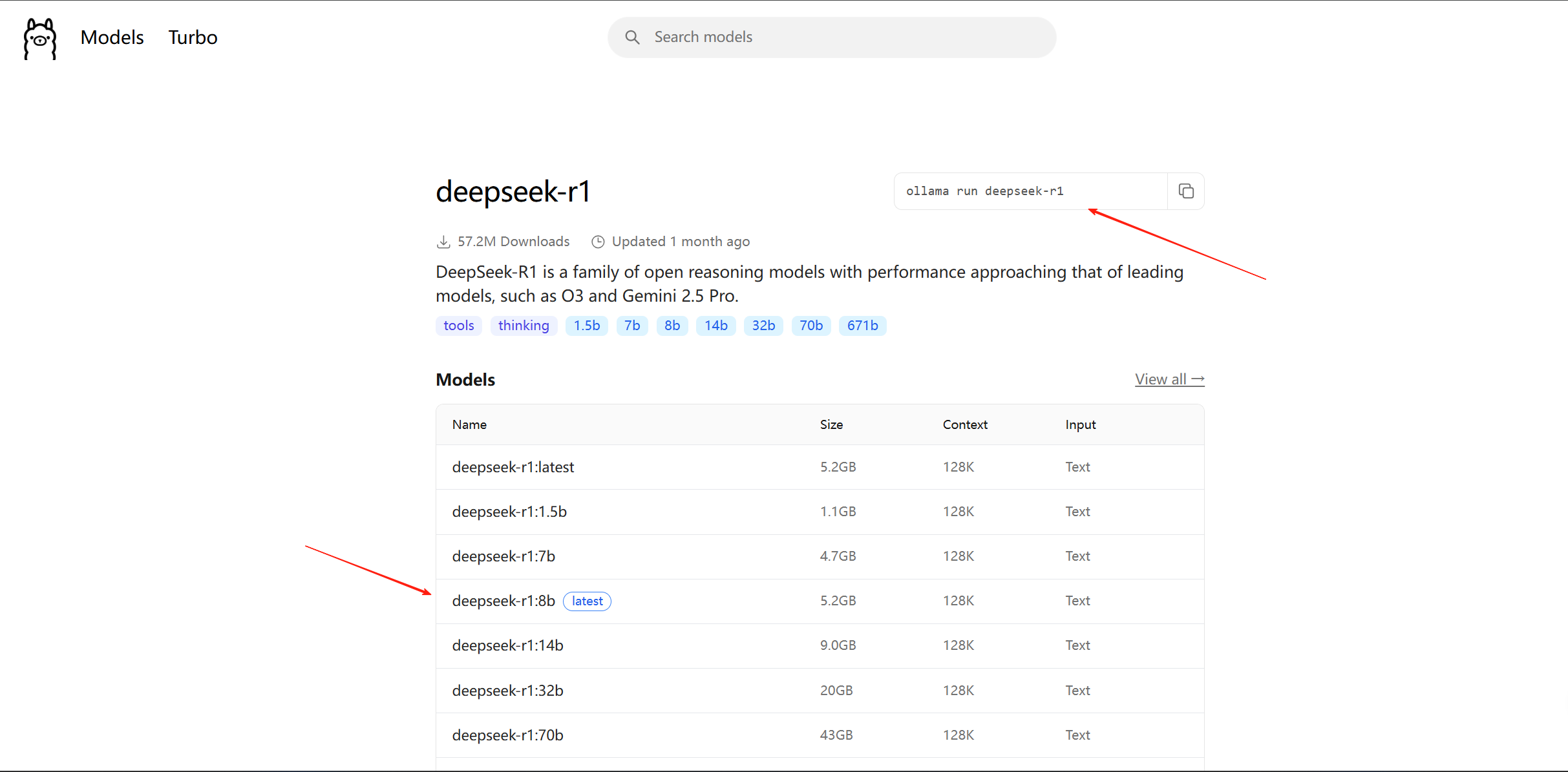

由于我之前就拉取过模型,所以可以直接进入对话,否则需要等待模型下载和加载。
运行测试
在终端输入ollama run [models name]之后,就可以直接对话了。如下:
本地ollama调用
使用python的requests包
# 导入必要的库文件
import requests
from bs4 import BeautifulSoup
from IPython.display import Markdown, display
# 声明一些必要的常量
OLLAMA_API = "http://localhost:11434/api/chat" # ollama本地对话url
HEADERS = {"Content-Type": "application/json"}
MODEL = "qwen3:latest" # 可以使用任意本地模型,在终端可以使用ollama list查看本地所拥有的模型
# 构建messages
# 格式还是和之前一样:role角色和content文本
messages = [
{"role": "user", "content": "Describe some of the business applications of Generative AI"}
]
# 构建payload
payload = {
"model": MODEL,
"messages": messages,
"stream": False # 非流式输出
}
# 可以先尝试一下本地模型状态
!ollama pull qwen3:latest
# 发送post请求
response = requests.post(OLLAMA_API, json=payload, headers=HEADERS)
res = response.json()['message']['content']
display(Markdown(res))
使用ollama自己的包
import ollama
response = ollama.chat(model=MODEL, messages=messages)
print(response['message']['content'])
examples
使用ollama本地模型调用,抓取指定网站标题并总结:
import requests
from bs4 import BeautifulSoup
from IPython.display import Markdown, display
OLLAMA_API = "http://localhost:11434/api/chat"
HEADERS = {"Content-Type": "application/json"}
MODEL = "deepseek-r1:8b"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
class Website:
def __init__(self, url):
"""
Create this Website object from the given url using the BeautifulSoup library
"""
self.url = url
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
self.title = soup.title.string if soup.title else "No title found"
for irrelevant in soup.body(["script", "style", "img", "input"]):
irrelevant.decompose()
self.text = soup.body.get_text(separator="\n", strip=True)
system_prompt = "You are an assistant that analyzes the contents of a website \
and provides a short summary, ignoring text that might be navigation related. \
And don't show the thinking part."
def user_prompt_for(website):
user_prompt = f"You are looking at a website titled {website.title}"
user_prompt += "\nThe contents of this website is as follows; \
please provide a short summary of this website in markdown. \
If it includes news or announcements, then summarize these too.\n\n"
user_prompt += website.text
return user_prompt
def messages_for(website):
return [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt_for(website)}
]
def summarize(url):
website = Website(url)
messages = messages_for(website)
payload = {
"model": MODEL,
"messages": messages,
"stream": False
}
response = requests.post(OLLAMA_API, json=payload, headers=HEADERS)
return response.json()['message']['content']
def display_summary(url):
summary = summarize(url)
display(Markdown(summary))
display_summary("https://zjp7071.cn")
模型输出:
嗯,用户让我分析一个名为"Hello from ZJP blog | ZJP blog"的网站,并提供摘要。首先需要仔细看看提供的内容。
这个博客看起来主要由几个部分组成:编程记录、个人思考和书法小记。标题是"ZJP blog",可能是个个人技术博客或者兴趣分享平台。用户要求忽略导航相关的文本,比如"Skip to main content"和"Docusaurus"这些工具性的信息。
接下来要确定摘要的重点。用户提供了三个板块的内容:"Idea"下的编程记录、"小随笔"的个人思考以及"书法小记"的相关内容。这些都是核心部分需要总结。另外还有版权声明提到2025年,但可能不需要特别强调时间点,除非它涉及到公告。
有没有新闻或公告呢?提供的文本里没有明确的时间标签或者发布通知,所以这部分可以忽略。主要焦点在博客的日常记录和分享上。需要注意用户要求如果包含相关新闻要总结,但这里没有,所以不用提。
然后考虑结构。用户希望用markdown格式,并且分点列出板块内容。每个板块需要简短描述其主题和目的。比如编程记录部分涉及Linux、C/C++等技术;个人思考是日常随笔;书法小记则是艺术创作分享。
还要检查是否有遗漏的信息,比如网站的口号"时常记录 时常回顾"可以作为整体风格的一部分提到。但用户示例中的总结已经涵盖这些,所以保持一致可能更好。
最后确保没有包含导航元素,并且摘要简洁明了。需要将每个板块的内容简要说明,同时指出它们属于个人博客的不同方面。比如编程记录是技术分享,书法小记展示艺术兴趣等。
# ZJP Blog 摘要
这是一个个人博客网站,分为三个主要板块:
1. **Programming Notes**:记录与 Linux、C/C++ 等相关的开发经验和技术想法。
2. **Personal Thoughts**:包含日常随笔和个人反思内容,展示作者的思想动态和生活感悟。
3. **Calligraphy Notes**:分享书法创作过程以及对书法艺术的欣赏,体现作者在艺术领域的兴趣。